
SQL for the rest of us
If you’re not a data scientist but you have questions, you want to know SQL. This guide will run through everything you need to get started: from technical topics to how to be a useful, smart teammate.
- What is SQL, exactly?
← JUMP HERE - Database schemas
← JUMP HERE - Basics of a SQL query
← JUMP HERE - Where and how to write SQL
← JUMP HERE - Query performance
← JUMP HERE - The advanced stuff: window functions, nesting, and such
← JUMP HERE - Practical tips for getting better and being a good teammate
← JUMP HERE - Where to learn more
← JUMP HERE
One very, very important caveat: SQL queries can write data to a database, not just read it. But that’s mostly for engineers and database admins, so this post will focus on reading data – probably 99% of what you want to do.
What is SQL, exactly?
Data in a database is almost never in the format you need it to be in. SQL is a programming language that lets you pull that data and rearrange it: add things together, group over time, replace dollar signs, you name it.
SQL stands for Structured Query Language, but that’s a misnomer; SQL isn’t actually a programming language like Javascript or Python. It’s a standard (like a blueprint) for how to query data, sort of like directions for building a language. Each database like PostgreSQL or MySQL has its own lil’ flavor of SQL, and that’s what’s more analogous to a language. So the specific syntax of how you write SQL depends on which database you’re using.
When you write SQL, you’re building what’s called a query: every “piece” of SQL you write will return one set of data. A SQL query can be as short as a few words, or as long as hundreds of lines. It’s sort of like making an order at a restaurant: you need to tell the database exactly what you want, and it will serve up the data you asked for. You’ll usually mess up the first few times before you get it right.
Database schemas
Before you understand how SQL works, you need to understand how data is stored. If you’re querying a database with SQL, chances are that database is organized as a series of tables, each with columns - think of a spreadsheet in Excel. A row is a single “data point” and a column is a type of data. So if we have a database full of orders that our customers made, one row would represent one order, while a column might be “order type” or “order date.”
You’ll often hear people (yes, they're people) refer to “schemas” in data related conversations. A schema is just a description of the structure of a database. A schema usually says something like “this database has these tables in it, each table has these columns, and these tables are related to each other in these ways.”
🚨 Confusion Alert 🚨
For reasons beyond me, PostgreSQL - one of the most popular relational databases – uses the word “schema” to refer to something else: a collection of tables. Most of the time you hear the word though, it will be in reference to database structure.
🚨 Confusion Alert 🚨
Poking through schemas are a useful way to better understand the data you’re working with and avoiding confusion down the road. Here’s what a schema might look like; you’ll notice there’s an entry for each column in the table and information about data types.
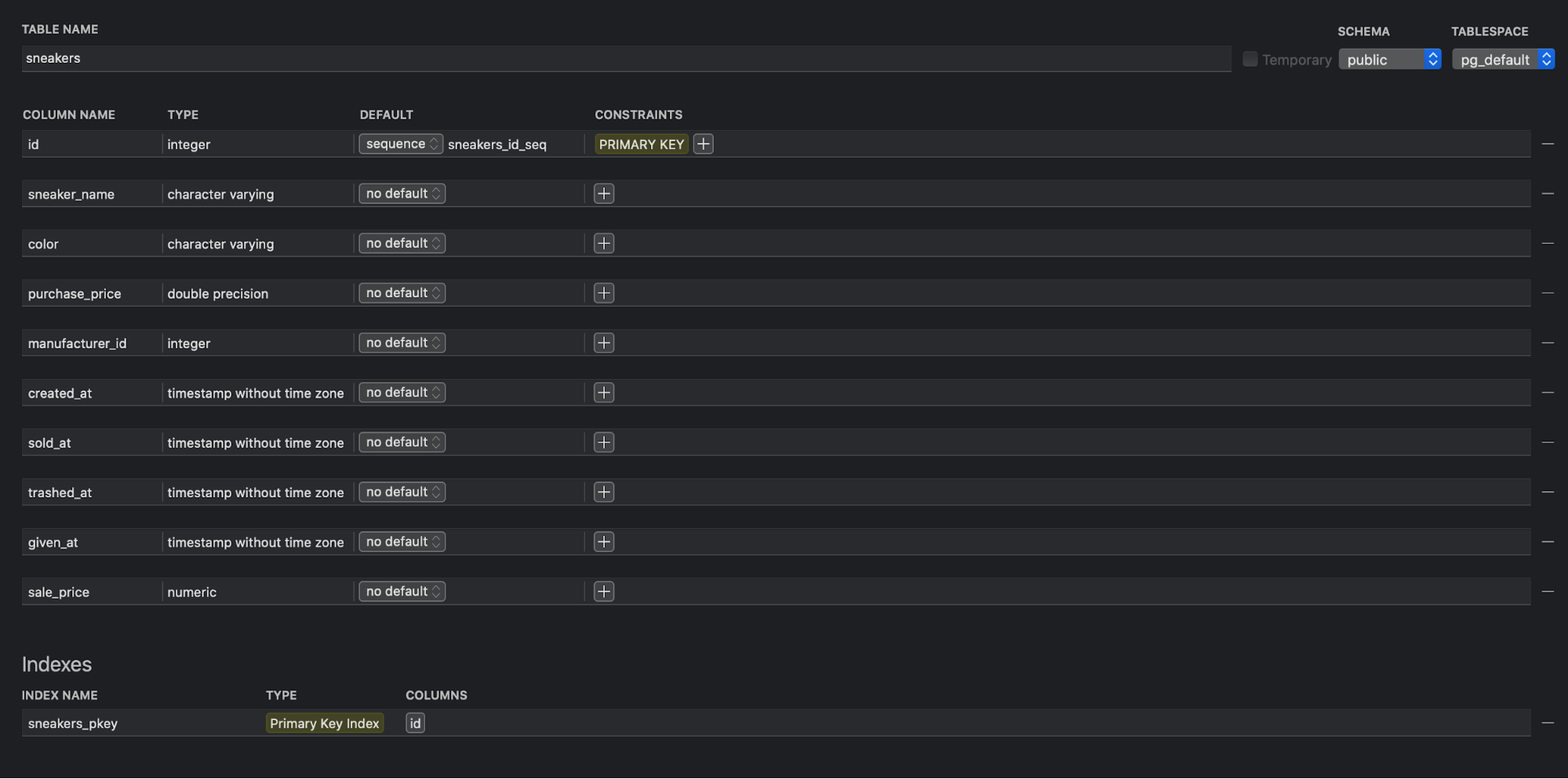
Basics of a SQL query
A SQL query is just telling the database what you want, but you need to do it in a specific order and format, plus use specific keywords.
1. The basic basics
Let’s start with a query and work backwards. We work at a DTC floss company named Flossier, and we want to analyze our order volume. This SQL query gets us the order ID, order date, and user ID for all orders that were made today.
SELECT
order_id AS id,
order_date ,
user_id
FROM orders
WHERE order_date = CURRENT_DATE()
ORDER BY order_date
You can probably get the gist of what this is doing: SELECTing the columns that we want FROM the table we want (it’s called “orders”) and filtering for WHERE the order_date is today (CURRENT_DATE()). Every SQL query will start with a SELECT and a FROM, and most of them will use a WHERE. Let’s run through these keywords in a bit more depth:
SELECT
The SELECT keyword designates which columns of data you want in your results. Tables will usually have more columns than you need for your analysis, so you’ll pick a subset of them in your query. If you want to return all columns in a table, you can write SELECT * instead of spelling out all of the individual column names.
🖇 Workplace Example 🖇
The phrase “select star” is pretty common in conversation among data and engineering teams. You might hear something like “select star isn’t working” which means that a table is down and not > queryable because you can’t select anything from it (i.e.
SELECT *doesn’t work).🖇 Workplace Example 🖇
The SELECT part of your query isn’t just where you pick columns, though; part of what makes SQL powerful is what you can do with the columns you’re selecting, like adding them together or transforming them. We’ll cover that in the “everything else” section.
FROM
A database usually has a bunch of tables, so you need to specify which table you want to pull your data from. Each query can only have one source table, but you can join other tables onto it: more on that later.
WHERE
The WHERE clause lets you filter the rows that you want; without it, your query will return every single row in the table. The general format works like this:
- The column you want to filter on (e.g.
order_date) - An operator (e.g. >,<,=)
- A filter value (
‘2020-01-01’)
In our query above, we only want to look at orders that happened today: so we use WHERE order_date = CURRENT_DATE(). CURRENT_DATE() is a built in function that gets whatever today’s date is.
ORDER BY
This (surprise!) lets you order your results by a column or by multiple columns. In our example query, we ordered the results by the order_date column. By default, ordering is ascending, but we can adjust this to ORDER BY order_date DESC to order descending.
AS
You can rename anything you’re working with in SQL - columns or tables - with the AS keyword. This is called aliasing, and it’s useful if you’ve got tables with long complex names that you want to skip typing out, a lot of similar sounding columns, or aggregations.
2. Grouping and aggregating
Where SQL gets really powerful is the ability to aggregate. Aggregation lets you answer questions like:
- How many orders have we gotten over the past few months?
- What’s the biggest order a customer has made in the past week?
- What’s our monthly revenue over the past year?
The answers to these questions require summing up or taking the max/min of things, and that’s pretty much what aggregation in SQL is. To aggregate, you’ll need to do two things: add an aggregation keyword into your SELECT statement, and add a GROUP BY clause at the end of your query. This here query gets us the number of daily orders since the beginning of the month:
SELECT
order_date,
COUNT(*)
FROM orders
WHERE order_date >= ‘2020-05-01’
GROUP BY order_date
The COUNT() function counts up the number of rows per order_date - we’re using the * inside because that’s the way that people typically do it (we could also have written COUNT(order_id) or any other column, and it wouldn’t make a difference). We also added a GROUP BY statement at the bottom to tell our database to aggregate that COUNT() per order_date and not per any other column.
Aggregation takes a little time to get comfortable with, so don’t sweat it.
3. Joining
Sometimes, all of the data you need will be in one table. Lucky you! Other times though, you’ll need to marry the data from two (or fifteen) different tables to get the answer to your question. SQL lets you JOIN tables together ON a shared column – also called a key – so you can make use of both data sets.
Example time! We’ve been pulling orders data - but what if we also want to know the name of the user who made the order? The problem is that the user’s name is in the users table, not the orders table. Thankfully, the user_id column exists in both tables and can use it to join them together:
SELECT
orders.order_id,
orders.order_date,
orders.user_id,
users.user_name
FROM orders
JOIN users
ON orders.user_id = users.user_id
Learning about JOINs is a whole trip, because there are different kinds: INNER JOINs, OUTER JOINs, LEFT JOINs, CROSS JOINs, and others too. There’s literally an entire website on the topic. Don’t sweat the details though; the more SQL you write, the more you’ll learn. For now, just make sure you understand the concept.
4. Everything else
There are thousands of other things you can do with SQL, like:
- Concatenate words together
- Round numbers
- Add and subtract date intervals
- Use conditional logic (if this then that)
It’s not quite a programming language, but it’s pretty powerful. We’ll cover a few more things in the advanced section below, but just keep in mind that if you can think of it, you can probably do it in SQL.
Where and how to write SQL
If you haven't written code before, what it means to "write" a program might not be intuitive. I was talking to my friend Zach about this topic recently, and I think he summarizes the thought process pretty well:

Writing a program actually is like writing a document, but it's a document of instructions. Your SQL query (the instructions) get sent to a database, that database reads and interprets them, and then it returns the results to you.
Like any programming language, people write SQL in a lot of different places; the most common is a SQL IDE, which stands for Integrated Development Environment. An IDE lets you connect to your database, write SQL queries, see the results, and adds other nice features like a schema explorer or the ability to download results into a spreadsheet.
There are literally hundreds of these; I use Postico (pictured above) for my personal PostgreSQL database, and used DBeaver for Presto when I was at DigitalOcean. And for some reason none of them have updated their website designs since 1993.
IDEs aren’t the only places you can write SQL. If your team is using a BI tool like Looker or Periscope, you can write SQL there: Looker's SQL Runner lets you run SQL directly in a browser tab (this is technically an IDE, but it’s in your browser, which isn’t the norm). You can also run SQL through the command line, like with psql, PostgreSQL’s command line interface.
Query performance
You want your queries to be fast. If your orders table has a few thousand rows in it, you don’t really need to worry about your query performance - things will generally be fast, no matter how you structure them. But if you’re working with a data set that’s voluminous (which is increasingly likely these days), you’ll need to start thinking about how fast your queries run and how you can optimize them to go faster. Query performance optimization sounds a lot scarier than it as, and you can nail down the basics pretty easily.
1. LIMITs
If you’re just looking at a few rows to get the feel for your table, you don’t need to return the entire results set from your query. You can use the LIMIT keyword at the end of your query to return a specific number of results. If we wanted the first 500 orders from today:
SELECT *
FROM orders
WHERE order_date = CURRENT_DATE()
ORDER BY order_date
LIMIT 500
A lot of the places you’ll write SQL (Looker, Periscope, etc.) will create default limits for you to avoid pulling too much data.
2. Indices
Database tables often have an index (or a few of them) to help speed up queries. If a column is indexed, it just means that some low level programming magic gets done in advance to make sorting and using that column faster than normal. But because indices are computationally expensive (they take up a lot of storage space), each table usually only has one or two. So if you can sort or filter on an indexed column instead of a regular one, your query will probably speed up.
3. Materialized views and intermediate tables
Every company wants to know how much money they’re making every month; instead of running a query on your raw orders data constantly, you can schedule that query to run every few hours and put the results into another table. Then you can just query the intermediate table and save a bunch of time. You can do this directly with materialized views, or use a workflow scheduler like Cron to do it in the background. If you’ve heard about ETL, a lot of it relates to this.
4. Common sense
When you get down to it, query performance is actually incredibly simple: the more data you need to scan, the longer it’s going to take. So be intentional and careful about how much data your queries need to look at. If you’re looking for the MAX() of an order_id in a table, your query will need to look at every row, and so on and so forth. Eventually, this kind of thinking just starts to overlap with algorithms and big-O notation.
The advanced stuff: window functions, nesting, and such
As with any programming language or domain, you can go pretty deep down the SQL rabbit hole: at bigger (or older) companies, you might even find entire job descriptions dedicated to administering and managing databases. For now, let’s cover a few more advanced topics that you might come across in your SQL journey:
1. Window functions
Ah, window functions - probably the most confusing and most oft-messed-up piece of SQL functionality out there. At their core, window functions are a set of functions that let you apply aggregations without reducing your dataset. To decode that statement, let’s go back to our original aggregation example, orders by day:
SELECT
order_date,
COUNT(*)
FROM orders
WHERE order_date >= ‘2020-05-01’
GROUP BY order_date
The data in the table is one row per order, but our aggregation reduced it to one row per order date. What if we wanted our data in the original row format, but with the daily count of orders in there too? Window functions let us do the same aggregation – orders per day – but attach it to each row instead of squashing the dataset.
SELECT
*,
COUNT(*) OVER (PARTITION BY order_date) AS daily_order_count
FROM orders
WHERE order_date >= ‘2020-05-01’
The syntax is really wacky, and you’ll also notice that we removed the GROUP BY statement at the end. This query gets us the same data as the first one, but in a completely different format. Another common use case for window functions is finding the first occurrence of something. Let’s say we wanted find every user’s first order – we could use something like this:
SELECT
*,
FIRST_VALUE(order_id) OVER (PARTITION BY user_id ORDER BY order_date) AS first_order_id
FROM orders
Mode’s blog is a great resource if you want to dive deeper into window functions and what they can do. I use them consistently and still haven’t gotten into more advanced parts of their functionality.
2. Nested queries
A nested query is a query inside another query 🤯. These are helpful for special use cases that require a lot of formatting – one popular example is getting the details of a customer’s first order, largest order, or combo aggregations like that. You’ll need to find something in one query, and then pull details on it in another one. Here’s an example that does just that:
SELECT *
FROM
(
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_number
FROM orders
)
WHERE row_number = 1
SQL filters (the WHERE clause) can only filter for data that exists in the table directly, so the row_number that you generated in the SELECT statement can’t be part of the filter. To get around that, we’re nesting the original query in another one and using the filter there. It’s not hard to see that nested queries run the risk of getting real complex real fast.
3. Common Table Expressions (CTEs)
Common Table Expressions let you define “mini tables” to use in your queries later on. You basically write a query, give it a name, and then you can query that query as a table. It’s a lot like nesting, but much more organized. Here’s an example that does exactly what the query above (in the nesting section) does:
WITH orders_with_row_numbers AS
(
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_number
FROM orders
)
SELECT *
FROM order_with_row_numbers
WHERE row_number = 1
It’s just a nested query, but in a clearer and more human readable order. We “call” our nested subquery orders_with_row_numbers, and then can SELECT FROM it like it’s a table. For longer queries that pull from a lot of different data sources, CTEs are cash money.
Practical tips for getting better and being a good teammate
Writing SQL is just a tool for achieving an outcome: whether you’re on the support, marketing, sales, or any other team, you’re probably reading this because you want to be more data driven. You should definitely learn SQL - but you should also learn what I like to call “SQL etiquette” or alternatively “how to not piss people off when you’re writing SQL.”
1. Name your stuff well
When you’re in throes of a complex query, it’s tempting to take shortcuts like aliasing your tables as a and b. Use informative, distinct column and table names so whoever is reading your query can understand it.
2. Comment your queries
If what you’re trying to accomplish isn’t intuitive, add comments into your SQL queries that explain your logic. For example – if you found a weird anomaly where some values for order_date are NULL and then used a COALESCE statement to fix them, say so! If you were confused writing it, people are going to be confused reading it.
3. If you see something, say something
So, so much of Data Science™ is finding and dealing with bugs. Duplicate rows, incorrect data formats, missing data, you name it - it’s going to happen. If you find something weird, bring it up! Here’s the thing though – at some point someone is going to need to fix it, so if you can, make it as easy for them as possible. If your company uses something like JIRA or Linear, create a ticket and write a few details about what’s wrong. Include your query and any investigation you’ve done to find the source of the error. Engineers will thank you for this, I promise.
4. Figure stuff out yourself
Your teammates are busy and don’t always want to answer your questions (ouch). When you get started working with data, you’re going to have a lot of questions - it’s natural. Do your best to answer some of those questions yourself, or at least get started:
- If you’re not sure what a column means, run through a few stats (min, avg, etc.)
- If you’re working with an intermediate table / materialized view, read the query that populated it
- If you’re not sure of a table name, search around for it
- Read any available company documentation about data sources
If you’re ever unsure what something means, you should not make decisions based on that data until you get a definitive answer. But do a little work in advance and make an extra effort, and you’ll be able to ask stronger, more pointed questions.
Where to learn more
The easiest and most reliable way to get better at SQL is – bear with me here – to actually write it. The more SQL you write the better you’ll get. I read a lot of content on the internet before I started working on a data team, but 2 weeks of writing queries all day did more for me than months of research. That being said, reading and listening are good too. Here are some resources that might help.
→ Interactive tutorials
- SQL Zoo
- SQLBolt
- LearnSQL
- W3 Schools – This is a huge site that covers a lot of programming languages. Quality is hit or miss
→ Courses / classes
- Codecademy SQL Course
- Khan Academy SQL Course
- The Complete SQL Bootcamp (Udemy)
- Learn SQL (Chartio)
- Intro to Relational Databases (Udacity)
- Vertabelo Academy
→ Books
- SQL in Ten Minutes (Ben Forta)
- Learning SQL (O’Reilly) – O'Reilly's stuff is always top notch
- Practical SQL (Anthony DeBarros)
- SQL Cookbook (O'Reilly)
- SQL All-in-One For Dummies
→ Blogs
→ Tools and IDEs
- SQLFiddle – tool to test SQL against different databases in your browser
- PopSQL
- Postico – PostgreSQL specific IDE
- TablePlus
- DBeaver
If you liked or hated this, share it on Twitter, Reddit, or HackerNews.